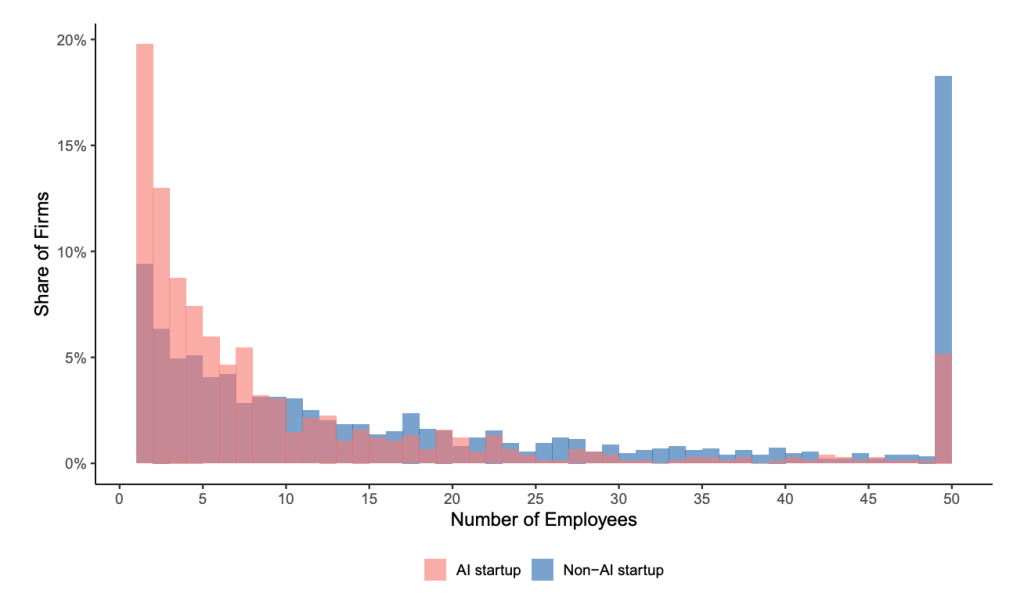
A recent paper from INSEAD and Harvard looked at close to 3,000 startups and found something that should interest anyone running a small firm. Matched like-for-like, same industry, same age, the ones built around AI ran about a quarter smaller than the ones that weren’t. In services, the gap reached roughly 70%. Fewer people, the same kind of work, and not because they were starving themselves of staff.
A smaller firm that is worth more
Across eleven startup batches from 2020 to 2024, the AI-native firms ran leaner and flatter, carried more senior people and fewer managers, and still raised more money and held higher valuations per head than their peers. The smaller size was buying more output per person, not papering over weaker companies. The effect was largest, near 70%, in services firms, the advisory-and-delivery work many of us sell. If your firm sells judgment rather than a shipped product, that number is aimed at you.
One example makes the shape concrete. An AI slide-deck company reached around $50M of annual revenue in about two years with a team of roughly 30, because making a deck became something the customer does inside the product instead of a job that lands in someone’s queue. A small team, a lot of output, because the work itself moved.
A fair caveat, which the paper makes and most write-ups drop: a leaner firm need not mean fewer jobs overall. Cheaper output tends to pull in more demand for it (the Jevons paradox: make something cheaper and we usually use far more of it), so the economy can end up with more firms and more total work even as each one shrinks.
The most telling result is one that didn’t show up the way you might expect. The AI-native firms in the study were about 2.6 times more likely than the rest to name worker-facing tools (ChatGPT, coding assistants, and the like) in their job ads, yet that heavier tool use predicted none of the structural differences: not the smaller size, not the flatter hierarchy. As the authors put it, “equipping workers with ChatGPT, Copilot, or Cursor does not, on its own, predict smaller firms.”
A large MIT study in 2025 found the mirror image: around 95% of corporate AI pilots delivered no measurable impact, with the failures traced to organisations bolting AI onto existing workflows rather than to the technology itself. Both point the same way. The gains come from redesigning the work, and the licence count barely matters.
What did track with firm size was where the AI sat. Used inside the firm to speed up work people already do, it moved the structure very little. Built into what the firm sells, so the customer generates the output directly, it tracked with the shrinkage. It is the same move Ben Thompson called an unbundling: the firms that pull ahead fold the act of making something real into the product, rather than keeping it a step their staff perform.
Governed delegation
What makes a firm AI-native, then, is how far it has rebuilt its work around what AI can do reliably and what still needs a person watching. Call it governed delegation: you hand the work to AI while keeping your hands on the rules, the boundaries, and the checking. Think of a restaurant that buys a dishwasher but keeps everyone rinsing each plate by hand first. It has added a machine and kept the old routine, so all it has really bought is cost. The gain shows up only when the workflow is rebuilt around what the machine does well.
Most of this conversation stays inside software teams, which is why the wider point gets missed. The same logic runs straight into sales, marketing, and operations, which is where I have spent the past several months testing it. I run most of OrchestratorAI’s own go-to-market this way: agents handle well-defined pieces of work, and my job is to set the rules and check the output rather than produce each piece by hand. Each group of agents runs in one of two modes, either nothing leaves the building until I have looked at it, or it runs on its own, shows me a sample, and escalates the exceptions. A task earns its way from the first mode to the second only after it stops throwing up things to fix, and some never do. Drafting a note to a high-value prospect stays under review; filling in a basic company profile from public sources does not need me hovering.
Running it this way taught me something the paper doesn’t quite reach: almost none of the governance had to be invented. We have spent decades building ways to govern people at work: audit trails and compliance checks, standard operating procedures, the maker-and-checker split in finance, code review and the ceremonies of Agile. In a human-only firm a lot of this sits heavy. It adds layers and breeds box-ticking, because people dislike being audited and tire of the checklist, so the control gets watered down to what the organisation or regulators will tolerate.
Point the same practices at AI agents and the weight largely lifts. An LLM is trained on how people work, so it takes direction roughly the way a person does, and the structure of the playbook carries over. The agent doesn’t resent the audit log or cut the SOP short when it’s busy, so a check that was costly to run on people is cheap to run on an agent. The procedures that were overhead in a human firm become the guardrails of an AI-native one. The autonomous SDLC (the software build-and-ship cycle, increasingly run by agents) is the clearest case I’ve come across: code review, the test gate, the staged rollout that always slowed teams down are exactly what lets an agent ship without a human reading every line.
The one catch here is that agents fail differently from people. They don’t commit fraud or get bored; they fabricate confidently and come apart on inputs a person would laugh off. So the controls transfer in shape, not in detail: you keep the independent check and the earned trust, but you point them at hallucination and weak grounding rather than at fatigue and dishonesty. Those rough edges are being ironed out quickly. Coding is the clearest case, where agents have grown markedly more reliable over the past year, and making AI broadly more dependable and harder to misuse is a major focus at the frontier labs, still some way from solved. The upshot is that there is already plenty an agent can be trusted to do well today, and the list keeps growing.
What it means if you run a small firm
The paper names the real bottleneck, and it isn’t access to AI, which everyone now has at much the same price. It is the mapping problem: working out where, in your particular business, AI actually pays off. That has no generic answer, and finding it is the work that’s left.
For a founder, the practical shift is that your scarce time moves from production toward direction and judgment, deciding where AI-handled work ends and where human review is non-negotiable. The closer you sit to pure services, the sharper that shift, which is presumably why the services number ran to 70%. Autonomy has to be earned, too: moving a task from supervised to self-running is a track record you build through logging and spot-checks, not a switch you flip. So the key question to put to your own firm is not which AI tools to buy, but which parts of the work can be governed at the boundary, and which still need a person on every output.
None of this is settled, and the unsettled part is the interesting one: deciding when a piece of work has earned its autonomy, and building the checks so you aren’t flying blind once it runs alone. Strikingly few firms in the data had actually managed it, which makes “AI-native” more aspiration than description for now, even among the companies wearing the label. That is the encouraging part. The tools are here and roughly evenly spread, so the advantage goes to whoever does the slow, unglamorous work of deciding what to hand over and what to keep a hand on.